We will begin this chapter with a short introduction to cellular automata, the computational model traditionally used in the study of self-replicating computing machines. We will then analyze existing self-replicating automata, and notably von Neumann's universal constructorand Langton's loop, before discussing the automata we developed in Embryonics. In the last section we will then describe the process we followed to adapt our self-replication mechanism to FPGAs.
Cellular automata are arrays of elements, or cells12, all behaving identically13, depending on the element's state. At regular, discrete intervals (iterations), the state of all elements is updated, depending on the current state of the element itself and that of its neighbors, according to a set of transition rules.
In order to illustrate the operation of cellular automata, we can examine one of the best known (and simplest) two-dimensional14 CA, commonly referred to as Life[32]. Life is a uniform two-dimensional cellular automaton where each element can be in one of only two states (aliveordead). The next state of an element depends on its current state and that of its eight closest neighbors (to the north, south, east, west, northeast, southeast, southwest, and northwest), and is calculated from a set of simple rules:
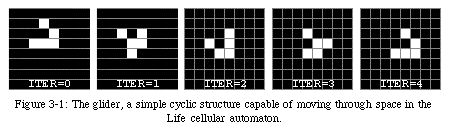
This very simple automaton is obviously not very powerful: the majority of initial configurations (the ensemble of the states of all elements at iteration 0) lead either to an empty space or to a collection of small, isolated cyclic patterns. One of the best-known of these patterns is the glider(Fig. 3-1, QT movie), a small structure capable of moving diagonally across the space. The glider is one of building blocks used to create machines which can become extremely complex (Fig. 3-2, QT movie).
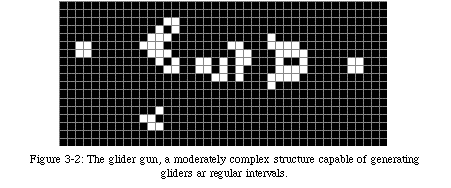
To resume, a cellular automaton is defined by the following parameters:
As should now be obvious, cellular automata are not a model which can easily be applied to digital hardware. The need for each element to access the transition rules, coupled with the large number of elements required for complex behavior, is a serious drawback for an electronic implementation. In addition, while cellular automata can be a powerful model for certain kinds of applications where the transition rules are relatively simple and known in advance (e.g., the modelization of the behavior of gases), the design of a complex automaton is extremely difficult: the absence of global rules imply that complex automata (i.e., configurations which span a large number of elements) have to be handled exclusively at the local level, and no formal approach is available to aid in this task.
Thus von Neumann, drawing inspiration from natural systems, attempted to develop an approach to the realization of self-replicating computing machines (which he called artificialautomata, as opposed to naturalautomata, that is, biological organisms). In order to achieve his goal, he imagined a series of five distinct models for self-reproduction [104, p. 91-99]: the kinematicmodel, the cellularmodel, the excitation-threshold-fatigue model, the continuousmodel, and the probabilisticmodel.
Of all these models, the only one von Neumann developed in some detail was the cellular model. Since it was the basis for the work of his successors, it deserves to be examined more closely.
The implementation as a cellular automaton is no less complex. Each element has 29 possible states, and thus, since the next state of an element depends on its current state and that of its four cardinal neighbors, 295=20,511,149 transition rules are required to exhaustively define its behavior. If we consider that the size of von Neumann's constructor is of the order of 100,000 elements, we can easily understand why a hardware realization of such a machine is not really feasible.
In fact, as part of the Embryonics project, we did realize a hardware implementation of a set of elements of von Neumann's automaton [12, 89]. By carefully designing the hardware structure of each element, we were able to considerably reduce the amount of memory required to host the transition rules. Nevertheless, our system remains a demonstration unit, as it consists of a few elements only, barely enough to illustrate the behavior of a tiny subset of the entire machine.
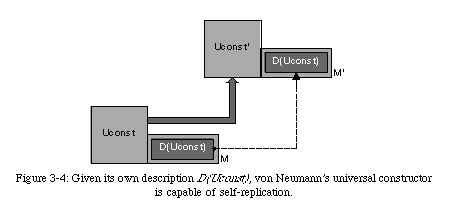
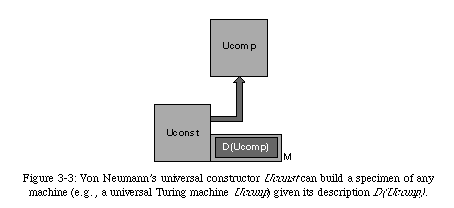
Before we continue, we should mention that von Neumann went one step further in the design of his universal constructor. If we consider the universal constructor from a biological viewpoint, we can associate the memory tape with the genome, and thus the entire constructor with a single cell (which would imply a parallel between the automaton's elements and molecules).
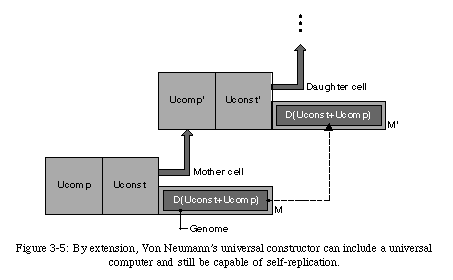
However, the constructor, as we have described it so far, has no functionality outside of self-reproduction. Von Neumann recognized that a self-replicating machine would require some sort of functionality to be interesting from an engineering point of view, and postulated the presence of a universal computer(in practice, a universal Turing machine, an automaton capable of performing any computation) alongside the universal constructor (Fig. 3-5).
The impossibility of achieving a physical realization did not however deter some researchers from trying to continue and improve von Neumann's work [11, 54, 71]. Arthur Burks, for example, in addition to editing von Neumann's work on self-replication [17, 104], also made several corrections and advances in the implementation of the cellular model. Codd [20], by altering the states and the transition rules, managed to simplify the constructor by a considerable degree. However, without in any way lessening these contributions, we can say that no major theoretical advance in the research on self-reproducing automata occurred until C. Langton, in 1984, opened a second stage in this field of research.
As a consequence of this approach, his automaton, commonly known as Langton's Loop[53], is orders of magnitude simpler than von Neumann's. In fact, it is loosely based on one of the simplest organs20 in Codd's automaton: the periodic emitter (itself derived from von Neumann's periodic pulser), a relatively simple structure capable of generating a repeating string of a given sequence of pulses.
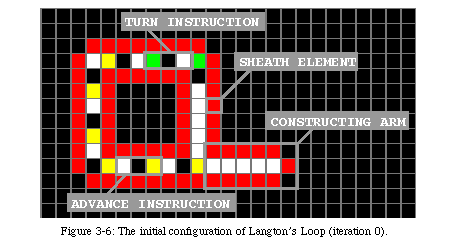
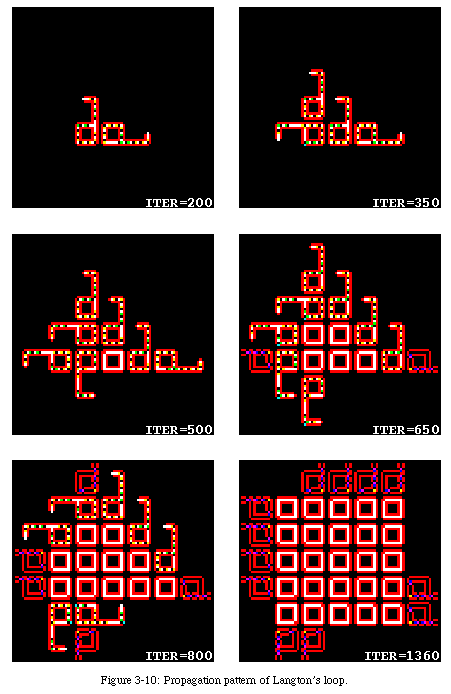
Langton's loop (Fig. 3-6, QT movie) is named after the dynamic storage of data inside a square sheath (red in the figure). The data is stored as a sequence of instructions for directing the constructing arm, coded in the form of a set of three states. The data turns counterclockwise in permanence within the sheath, creating a loop.
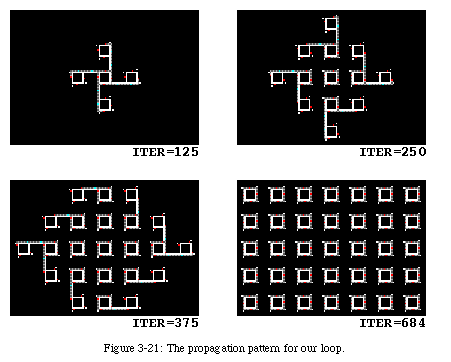
The sequential nature of the self-reproduction process generates a spiraling pattern in the propagation of the loop through space (Fig. 3-10, QT movie): as each loop tries to reproduce in the four cardinal directions, it finds the place already occupied either by its parent or by the offspring of another loop, in which case it dies (the data within the loop is destroyed).
Langton's loop uses 8 states for each of the 86 non-quiescent cells making up its initial configuration, a 5-cell neighborhood, and a few hundred transition rules (the exact number depends on whether default rules are used and whether symmetric rules are included in the count).
Further simplifications to Langton's automaton were introduced by Byl [18], who eliminated the internal sheath and reduced the number of states per cell, the number of transition rules, and the number of non-quiescent cells in the initial configuration. Reggia et al. [82] managed to remove also the external sheath, thus designing the smallest self-replicating loop known to date. Given their modest complexity, at least relative to von Neumann's automaton, all of the mentioned automata have been thoroughly simulated.
Nevertheless, von Neumann's constructor and Langton's loop are the models which most closely approach our requirements. Therefore, we decided to follow tradition in developing our own approach to self-replication by using cellular automata as an environment to study the issue.
As we already mentioned, there is no formal approach to the development of complex cellular automata. The design of such systems poses therefore considerable problems, since few of the available tools are suited for the task. In particular, no efficient tools were available to help the user in determining the local transition rules necessary to obtain a complex global behavior (cellular automata are mostly used to simulate physical phenomena, where the rules are usually well known). Our first task was therefore to design a software application which would allow us to generate the required rules as easily as possible. The resulting program (described in Appendix A) is, to the best of our knowledge, unique, and proved an invaluable tool in our research.
Equipped with a reasonably powerful tool, we started developing a new automaton capable of self-replication. Considering the complexity of von Neumann's constructor, we decided to draw inspiration from the much simpler Langton's loop, but, as we will see, we had to develop a completely novel mechanism to enable us to circumvent its drawbacks.
At first glance, this might seem a relatively trivial drawback, which could be overcome by modifying the loop. Such a modification, however, turns out to be very difficult. In fact, to exist in a finite space, and assuming that the automaton has no a prioriknowledge of the location of the boundaries (a safe assumption, since CA elements have only knowledge of their immediate neighborhood), the loop needs either to verify that enough space is available before it starts the replication process, or else some way to destroy the constructing arm if it detects a boundary during the self-replication process. Either of these mechanisms would require a major structural modification to Langton's loop.
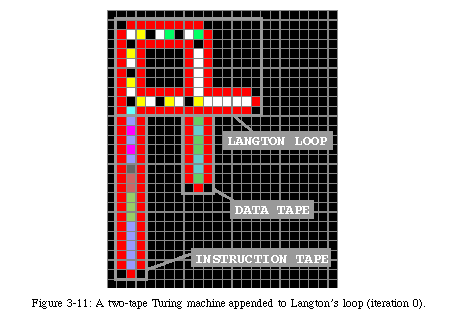
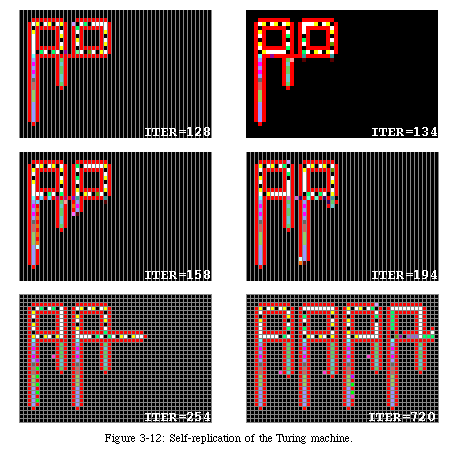
Thus, rather than trying to adapt Langton's automaton to a finite space, we decided to develop an entirely new mechanism, designed specifically to exist in a finite, but arbitrarily large, space, and at the same time capable, unlike Langton's loop, to have a functionality in addition to self-replication. Adding functionality to Langton's loop, in fact, is not possible without major alterations. As a matter of fact, in the course of our research, we did develop a relatively complex automaton (Fig. 3-11, QT movie) in which a two-tape Turing machine was appended to Langton's loop [77]. This automaton, developed in our laboratory by J.Y. Perrier as a semester-long research project under the supervision of Prof. J. Zahnd, exploits Langton's loop as a sort of "carrier" (Fig. 3-12, QT movie): the first operation of Perrier's loopis to allow Langton's loop to build a copy of itself (iteration 128: note that the copy is limited to one dimension, since the second dimension is taken up by the Turing machine). The main function of the offspring is to determine the location of the copy of the Turing machine (iteration 134). Once the new loop is ready, a "messenger" runs back to the parent loop and starts to duplicate the Turing machine (iterations 158 and 194), a process completely disjoint from the operation of the loop. When the copy is finished (iteration 254), the same messenger activates the Turing machine in the parent loop (the machine had to be inert during the replication process in order to obtain a perfect copy). The process is then repeated in each offspring until the space is filled (iteration 720: as the automaton exploits Langton's loop for replication, meeting the boundary of the array causes the last machine to crash).
While preserving some of the more interesting features of Langton's loop, we nevertheless introduced some basic structural alterations:
As should be obvious, while our loop owes to von Neumann the concept of constructing arm and to Langton (and/or Codd) the basic loop structure, it is in fact a very different automaton, endowed with some of the properties of both.
We have seen that von Neumann's automaton is extremely complex, while Langton's loop is very simple. The complexity of our automaton is more difficult to estimate, as it depends on the data circulating in the loop. The number of non-quiescent elements making up the initial configuration depends directly on the size of the circulating program. The more complex (i.e. the longer) the program, the larger the automaton (it should be noted, however, that the complexity of the self-reproduction process does not depend on the size of the loop). The number of states also depends on the complexity of the program. To the 5 "basic" states used for self-reproduction (see description below) must be added the "data states" (at least one) used in the program, which must be disjoint from the basic states. The number of transition rules is obviously a function of the number of data states: in the basic configuration (i.e., one data state), the automaton needs 692 rules21 (173 rules rotated in the four directions).
The complexity of the basic configuration is therefore in the same order as that of Langton's and Byl's loops, with the proviso that it is likely to increase drastically if the data in the loop is used to implement a complex function.
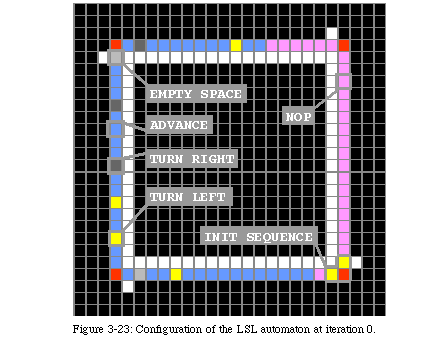
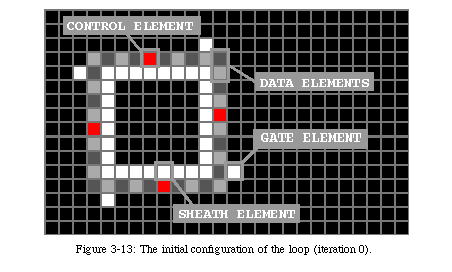
The elements of the array require five basic states and at least one data state (Fig. 3-13, QT movie). State 0 (black) is the quiescent state: it represents the inactive background. State 1 (white) is the sheath state, that is the state of the elements making up the sheath and the four gates. State 2 (red) is the activation stateor control state. The four elements in the loop directing the reproduction are in state 2, as are the messengers which will be used to command the constructing arm and the tip of the constructing arm itself for the first phase of construction, after which the tip of the arm will pass to state 3 (light blue), the construction state. State 3 will construct the sheath that will host the offspring, signal the parent loop that the sheath is ready, and lead the duplicated data to the new loop. State 4 (green), the destruction state, will destroy the constructing arm once the copy is completed. In addition to these states, two additional data states(light and dark grey) represent the information stored in the loop. In this example, they are inactive, while the next section describes a loop where they are used to store an executable program.
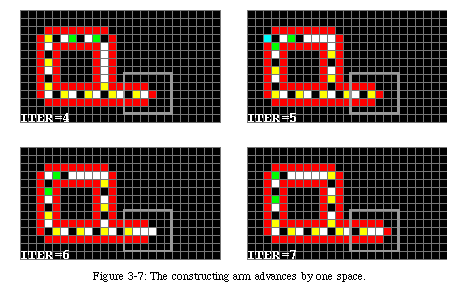
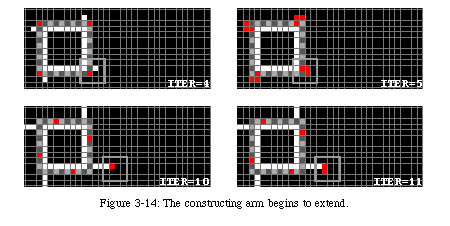
Once the iterations begin, the data starts turning counterclockwise around the loop. Nothing happens until the first control element reaches a corner of the loop, where it checks the status of the gate. Since the gate is open, the control element splits into two identical elements: the first continues turning around the loop, while the second starts extending the arm (Fig. 3-14). The arm advances by one position every two iterations.

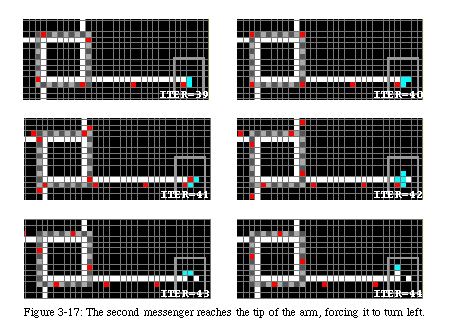
When the first messenger reaches the tip of the arm, the tip, which was until then in state 2, passes to state 3 and continues to advance at the same speed (Fig. 3-16). This transformation tells the arm that it has reached the location of the offspring loop and to start constructing the new sheath.

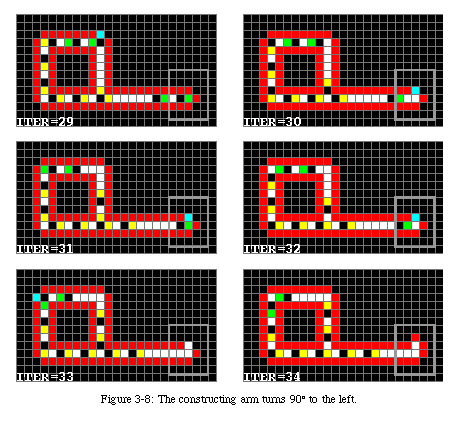
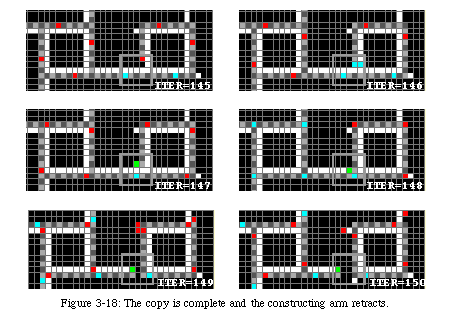
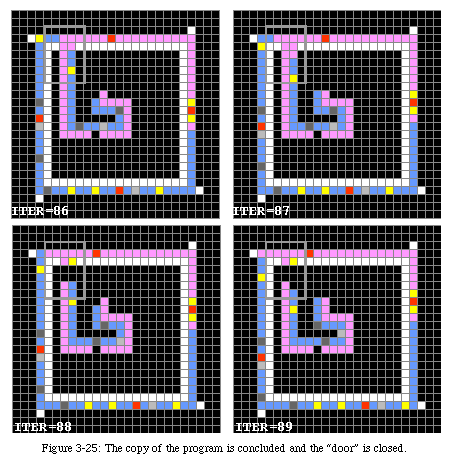
The next three messengers will force the tip of the arm to turn left (Fig. 3-17), while the fourth will reach the tip as the arm is closing upon itself (Fig. 3-18). It causes the sheath to close and then runs back along the arm to signal to the original loop that the new sheath is ready.
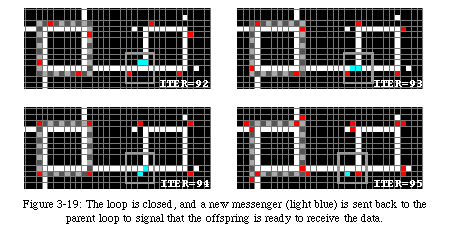
Always followed by the data, it runs around the sheath until it has reached the junction where the arm folded upon itself (Fig. 3-20). On reaching that spot, it closes the loop and sends a destruction signal (green) back along the arm. The signal will destroy the arm until it reaches the corner of the original loop, where it closes the gate to avoid further copies.
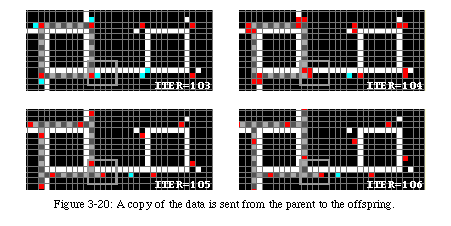
After 121 time periods the gates of the original automaton will be closed and it will enter an inactive state, with the understanding that it will be ready to reproduce itself again should the gates be opened.
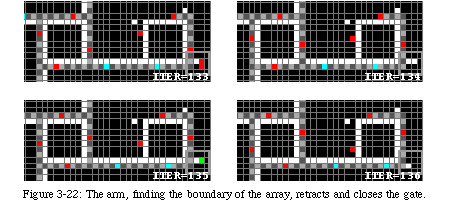
The main advantage of the new mechanism is that it becomes relatively simple to retract the arm if an obstacle (either the boundary of the array or another loop) is encountered, and therefore our loop is perfectly capable of operating in a finite space. In the example above, the right border of the figure corresponded to the boundary of the array: when the offspring tried to replicate towards the east, the arm, it found its way blocked, simply retracted and closed its gate (Fig. 3-22).
For this example, we have used 5 data states, each representing an instruction for the construction of the letters: advance, turn left, turn right, empty space, and a NOP (no operation) instruction to fill the remaining space in the loop. The construction requires 330 additional rules.
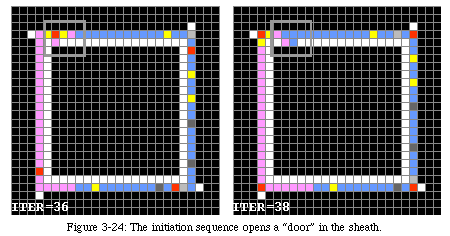
The operation of the program is fairly straightforward. When a certain initiation sequencewithin the loop arrives to the top left corner of the loop, a "door" is opened in the internal sheath (Fig. 3-24). The rest of the program, as it passes by the door in its rotation around the loop, is duplicated and one of the copies is sent to the interior of the loop, where it is treated as a sequence of instructions which direct the construction of the three letters. Once the duplication is complete (i.e., when the first NOP instruction reaches the opening), the door is closed and the sheath reset, except for a flag which indicates that the task has already been completed and prevents the door from being opened again (Fig. 3-25).
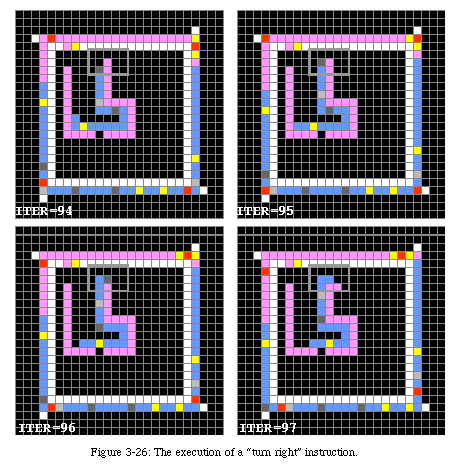
The construction mechanism itself is somewhat similar to the method Langton used in his own loop, and is based on a modified constructing arm. The advance instruction causes the arm to advance by one element, the turn left and turn right (Fig. 3-26) instructions cause the arm to change direction, and the "empty space" instruction produce a gap in the arm (to separate the letters).
This is a simple demonstration of one way in which the data in the loop could be used as an executable program. Of course, many other methods can be envisaged, but unfortunately it would be very hard, if not impossible, to obtain computationally interesting self-replicating systems using "pure" cellular automata.
In fact, CA are, by definition, closed systems: all the information must be present in the array at iteration 0 (in our case, all the data for the system must be included in the initial loop). Since useful computation would require that each of the offspring execute a different function (or at the very least, the same function on different data), the requirement that all information be stored in the parent loop is too restrictive for our needs.
At this stage we therefore decided to stop further development of self-replicating machines in the cellular automaton environment, and attempt to transfer the accumulated experience to the design of our FPGA.
One of the main differences between our loop and Langton's lies in the two-phase mechanism of self-replication: while in Langton's loop the process is indivisible, we can identify two distinct phases in the self-replication of our loop: first the arm "reserves" the space required for the offspring, and only then the data are copied. In other words, the process can be divided into a structural phase, where the structure of the loop is set into the empty space, and a configuration phase, where the functionality of the parent is sent into the offspring.
In defining an FPGA architecture to implement the process of self-replication, the requirements of cellular automata conflict with an efficient use of hardware in a number of respects, notably where the configuration phase is concerned: the loop structure, so well suited to cellular automata, represents an unacceptable waste of material in an electronic circuit (using the loop's perimeter implies that the interior is wasted). As we will see in the next chapter, to efficiently exploit the surface of programmable logic we adopted a more conventional approach to the configuration of the array. However, the separation between the two phases of our self-replication strategy means that the drawbacks of the configuration phase need not necessarily apply to the structural phase.
The greatest obstacle in implementing self-replication in our FPGA lies in the fact that we cannot a prioridefine the size of our cells. Thus, we require a system capable of configuring a finite two-dimensional array of elements (the FPGA) as a two-dimensional array of identical configuration blocks, each containing a single cell. Obviously, this problem bears a considerable resemblance to self-replication in cellular automata: similarities exist between the CA elements and the FPGA elements (molecules) and between a loop and a processor (cells). By exploiting this resemblance, we can observe that the structural phase of our self-replication mechanism can indeed be a solution to the problem of configuring our FPGA.
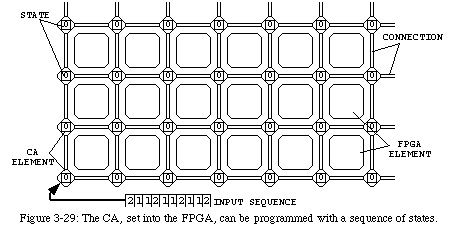
If we consider the FPGA before configuration as an array of CA elements in the quiescent state, we can design a very simple automaton [60, 92] (Fig. 3-28, QT movie) capable of subdividing the surface of programmable logic into square blocks of variable size (we thank André Stauffer for the realization of this automaton). The initial configuration (iteration 0) of this automaton is somewhat non-conventional: the configuration of an FPGA is effected by a one-dimensional sequence of bits (the configuration bitstream), while conventional cellular automata operate from an initial two-dimensional structure already in place at iteration 0. To overcome this difference, we designed an initial configuration which simulatesa configuration stream: the sequence of states stored alongside the (inert) white band represents the data stored in a memory, and as time progresses it slides along the band to enter the quiescent area (the empty FPGA) from its lower left corner.
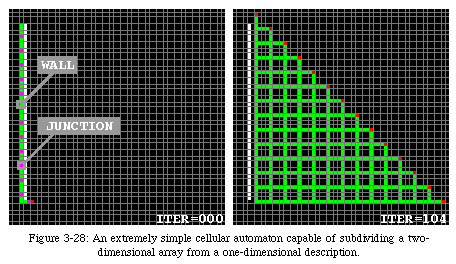
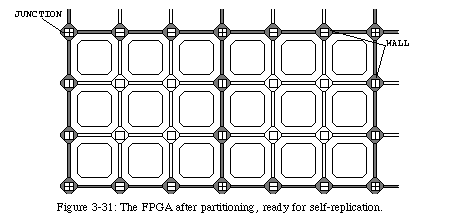
The mechanism used in this automaton is very similar to the one used to direct the constructing arm in our loop, but is much simpler. It uses only two active states22: a wall state(green), which defines the borders of the blocks, and a junction state(purple), which defines the intersections between walls. Operation starts when the first data element (always in the junction state) leaves the inert band. From this first element, two branches start to propagate: one to the north and one to the east. The branches will advance at half speed, leaving walls on their path. Meanwhile, data is leaving the band at full speed. Whenever a junction state reaches the tip of the branches, it causes a further split: again, one branch to the north and one to the west. It should then be obvious that in the end, the quiescent area will have been divided into square blocks of a size corresponding to the distance between two junction states in the data tape.
This very simple cellular automaton could thus allow us to achieve self-replication in an FPGA by transforming a one-dimensional string of information to a two-dimensional array of square blocks of programmable size: the elements of the cellular automaton form the perimeter of the block, and thus perform the same function as the membranewhich surrounds a biological cell. Moreover, the automaton is simple enough that a hardware implementation becomes straightforward.
Fig. 3-30 shows the effect of entering the simple state sequence shown in Fig. 3-29 into the automaton. As for the automaton described above, only two active states are used: the wall state, labeled 1, and the junction state, labeled 2. The operation of this automaton is identical to that of the one shown in the previous subsection, with a single exception: the corners of the blocks remain in a distinctive junction state after the end of the propagation. This small difference, which in fact allows us to reduce the complexity of the hardware, is a typical example of the difficulties of designing a cellular automaton for hardware implementation: an increase in the complexity of the automaton can, as often as not, result in a decrease in the complexity of the hardware required to implement it.
In the end, we were able to design an extremely simple mechanism which allows us to partition the FPGA into a set of square blocks of programmable size (shown in Fig. 3-31 with a more intuitive symbolic representation of the CA states), the indispensable preamble to self-replication. Once the membrane is in place, we can, as we will see in the next chapter, use it to direct the configuration of the FPGA: we can exploit the information contained in the cellular automaton to automatically replicate the configuration of a single block into all of the blocks in parallel. We can, in short, achieve the self-replication of electronic circuits23 .
12.Again, standard terminology creates a problem with regards to our project. The elements of cellular automata are usually referred to as cells, but do not really resemble biological cells (they do not contain a genome). We will thus call them elements or sometimes molecules, the closest biological analog.
13.Elements with different behaviors are allowed in some CAs, usually called non-uniform. Since all the models used in this thesis are uniform, however, we can consider all elements to have identical behavior.
14.There is no theoretical limit to the number of dimensions of a cellular automaton. However, CA being, essentially, graphic-oriented models, the need to display their activity imposes a practical limit: the greatest majority of existing automata are either one- or two-dimensional, and while we are aware of the existence of some three-dimensional automata, we have no knowledge of any implementation in four or more dimensions. All of the automata used to study self-replication are two-dimensional.
15.A typical lookup table entry for a 2-state 9-neighbors automaton would have the form:
16.For example by assuming a "default" behavior (e.g., the next state will remain equal to the current state unless a rule specifies otherwise).
17.Let us remember that the computers von Neumann was familiar with were based on vacuum-tube technology, and that vacuum tubes were much more prone to failure than modern transistors. Moreover, since the writing and the execution of complex programs on such systems represented many hours (if not many days) of work, the failure of a system had important consequences in wasted time and effort.
18.You will note that we use the terms self-replication and self-reproductioninterchangeably. In reality, the two terms are not really synonyms: self-reproduction is more properly applied to the reproduction of organisms, while self-replication concerns the cellular level. As we will see, the more correct term to use in this circumstance would probably be self-replication, but since von Neumann favored self-reproduction, we will ignore the distinction.
19.The memory of von Neumann's automaton bears a strong resemblance to the biological genome. This resemblance is even more remarkable when considering that the structure of the genome was not discovered until after the death of von Neumann.
20.An organ in this context can be seen as a self-supporting structure capable of a single sub-task.
21.By default, all elements remain in the same state.
22.Some additional states are indeed required for the operation of the automaton, but they are either inert (e.g., the black quiescent state and the white band) or transient.
23.The process also resembles the biological process of cloning. It is self-replication in the sense that it is handled by the hardware itself, and it is cloning in the sense that all data come from an external source.